R3: 3D Reconstruction via Relative Regression
arXiv, 2026
project page / arXiv / code
Assembles confidence-guided pairwise poses into trajectories, enabling a 0.3B model to match 1B baselines.
陈星宇
I am a PhD student jointly enrolled at Westlake University and Zhejiang University, in the Inception3D Lab, co-supervised by Anpei Chen and Andreas Geiger.
I am fortunate to work with Yuliang Xiu at Endless AI Lab and interned at Tencent AI Lab, collaborating with Xuan Wang and Qi Zhang. I got my M.S. from Xi'an Jiaotong University and my B.S. from Chongqing University.
I work on spatial intelligence across computer vision, machine learning, computer graphics, and robotics.

The world we see is constantly changing: how do intelligent systems generalize to new observations? This question led me to quest for an understanding of the mechanisms underlying spatial intelligence and to develop methods for enabling artificial intelligence with this remarkable capability.
Specifically, I am investigating how generalizability can emerge from reusable 3D & 4D representations, how these representations of the dynamic 3D world could be learned from images & videos, and how inductive biases could serve as expert knowledge to reduce unknown parameters and make learning more efficient.
Equal Contribution *, Corresponding Author †, Project Lead ⚑
arXiv, 2026
project page / arXiv / code
Assembles confidence-guided pairwise poses into trajectories, enabling a 0.3B model to match 1B baselines.

European Conference on Computer Vision (ECCV), 2026
A global scene tokenizer that moves beyond pixel-wise redundant tokens.

IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
project page / arXiv / code
Synthesising 4D dynamic objects from single monocular video.

International Conference on Learning Representations (ICLR), 2026
China3DV 2026 Top 5 Paper
project page / arXiv / code
A simple state update rule to enhance length generalization for CUT3R.

International Conference on Learning Representations (ICLR), 2026
project page / arXiv / code / interactive demo
Online human-scene reconstruction in One model, One stage.

IEEE/CVF International Conference on Computer Vision (ICCV), 2025
project page / arXiv / code / interactive demo
Disentangles DUSt3R attention maps and repurposes them for training-free 4D reconstruction.

IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
project page / arXiv / video / code / demo / gallery
Uses novel-view synthesis to probe texture and geometry awareness in visual foundation models.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
project page / arXiv / paper / code / supplementary / video / poster
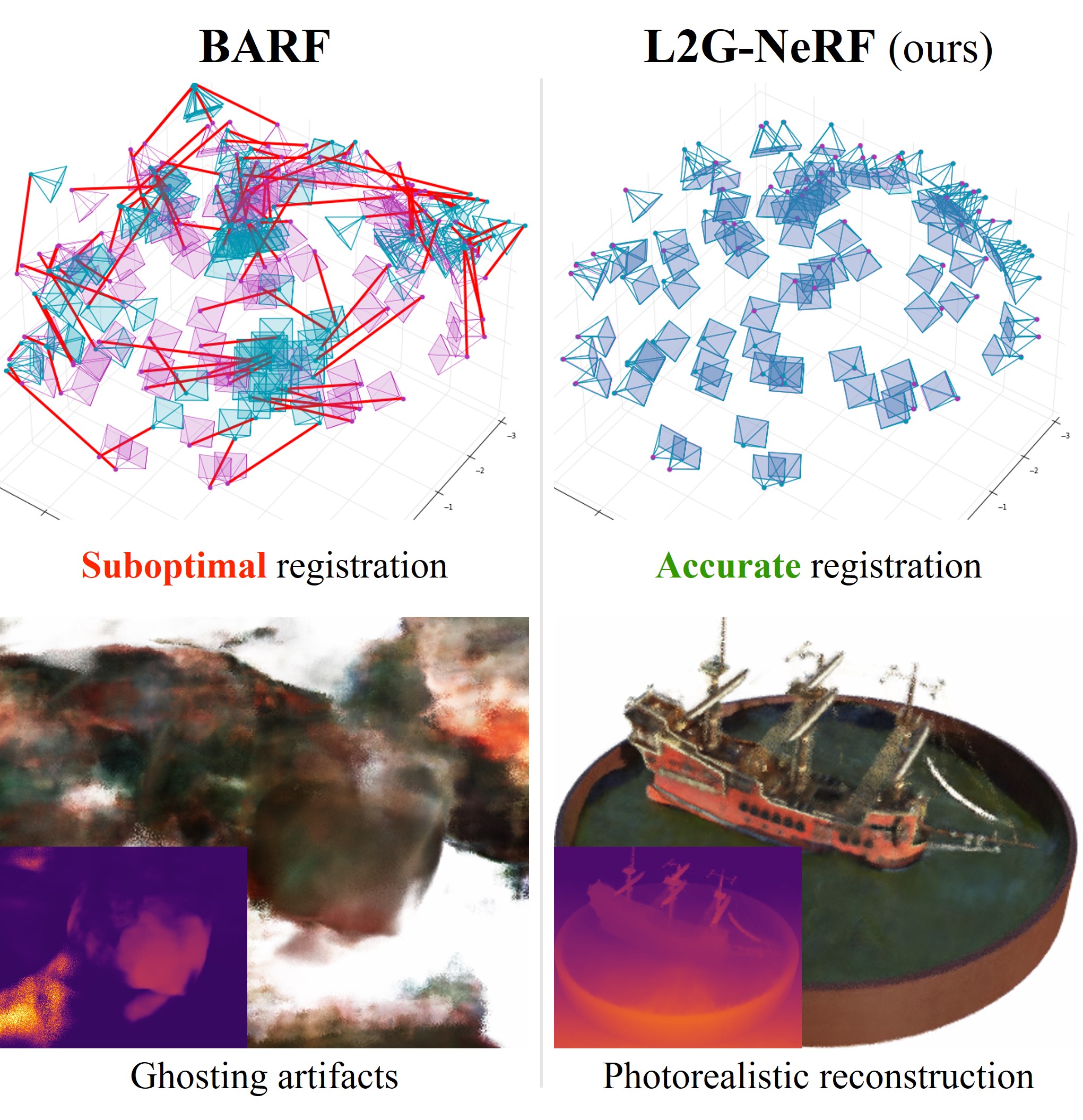
Couples local and global alignment with differentiable solvers for robust bundle-adjusting NeRF.

IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
project page / arXiv / paper / code / supplementary / video / poster
Separates high-frequency human appearance from 3D volume and encodes it as 2D textures for real-time rendering and retexturing.
IEEE International Conference on Robotics and Automation (ICRA), 2023
arXiv / paper / code / video / poster
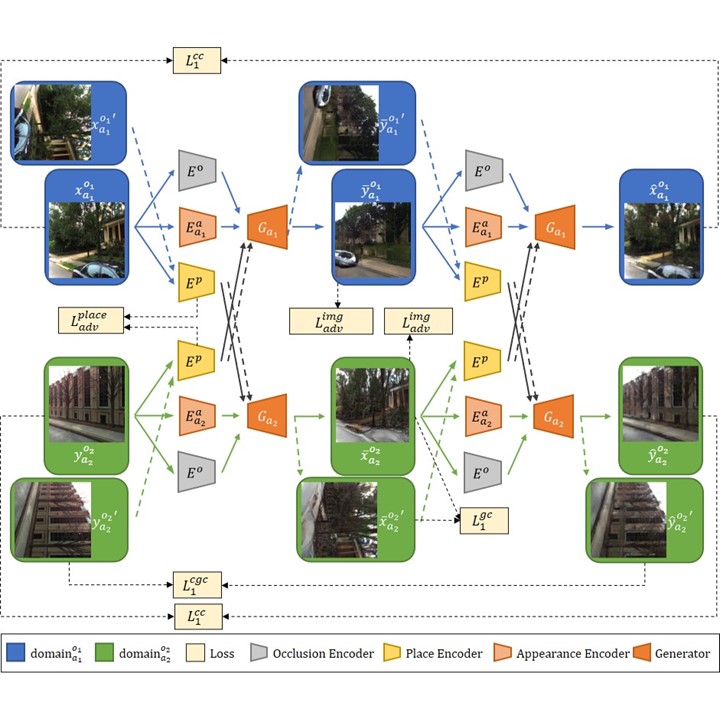
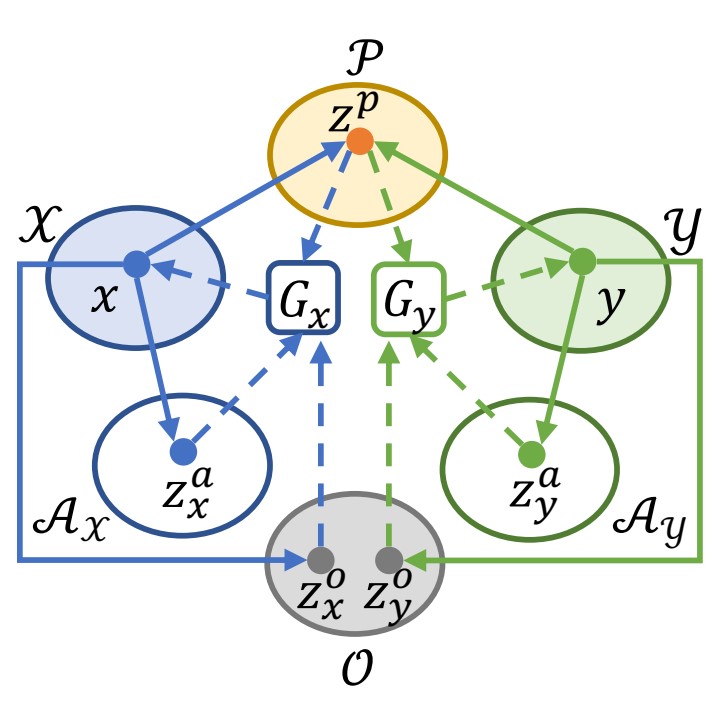
Disentangles place, appearance, and occlusion factors, then uses the place code as a retrieval descriptor.
IEEE Robotics and Automation Letters (RA-L), 2022
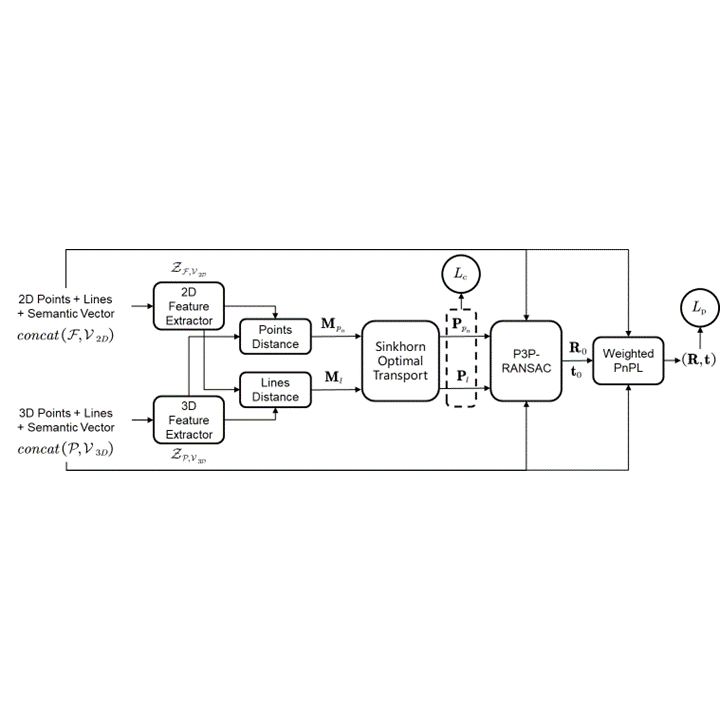
Estimates camera poses from sparse semantic maps through learned 2D-3D point-line correspondences.
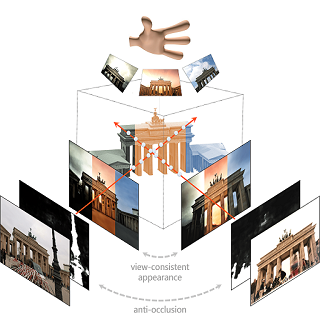
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
project page / arXiv / paper / supplementary / code / video / poster
Recovers NeRF from tourist photos with variable appearance and occlusions, enabling occlusion-free renderings with hallucinated appearance.
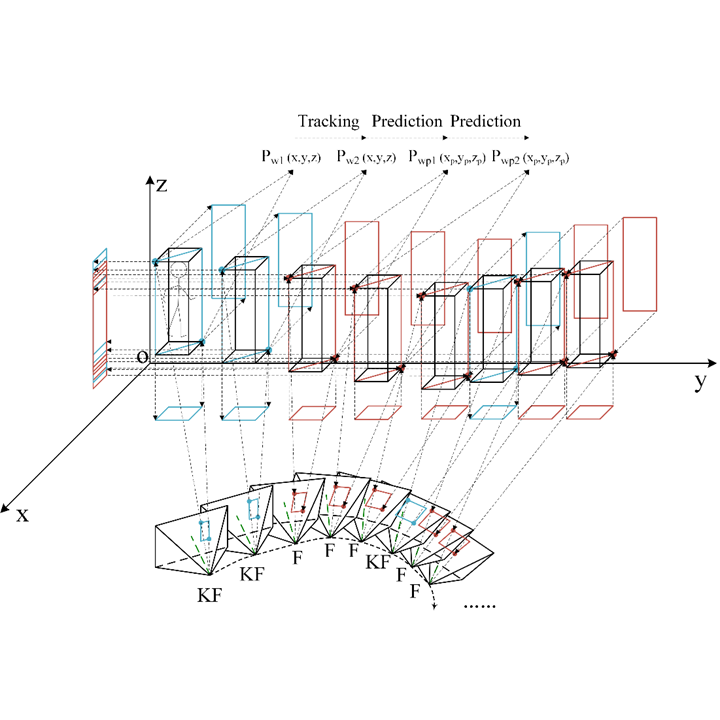
IEEE Intelligent Vehicles Symposium (IV), 2020
Detects only keyframes and predicts dynamic objects in remaining frames for efficient semantic mapping.
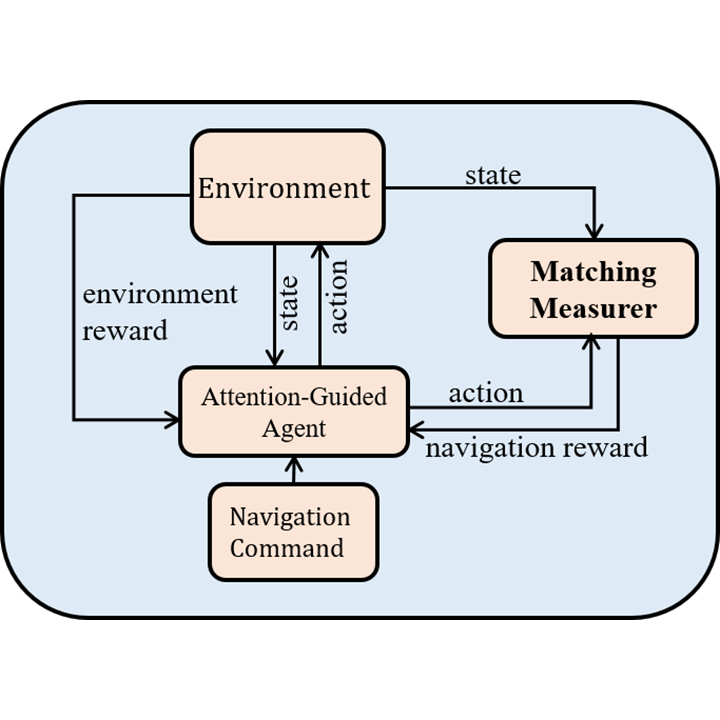
IEEE International Conference on Robotics and Automation (ICRA), 2020
Matches navigation commands with smooth rewards to discriminate sub-optimal driving actions.
I am passionate about bridging the physical and digital worlds by building next-generation AR and robotics.





Sharing the intuition of dealing with dynamic objects in our previous work and giving a prospect of handling the tracking problem via neural fields.

Introduction about Neural Radiance Fields (NeRF) for unconstrained photo collections, including NeRF, NeRF in the Wild, and Ha-NeRF.
I gratefully acknowledge support from the following programs and organizations.
Machine Learning, Teaching Assistant, Westlake University